

Anthropic lanserar smartare Claude 3.7 Sonnet AI som kan spela Pokémon Red som ett lovande proffs
Anthropic har lanserat Claude 3.7 Sonnet, sin senaste AI-chatbot med avancerad kodning och djupt tänkande för att lösa komplexa uppmaningar och programmeringsuppgifter med hjälp av ett större 128K token-fönster.
I likhet med andra nyligen släppta AI-modeller för stora språk av OpenAI och xAI, gör tillägget av utökat tänkande att Anthropics senaste AI kan ta extra tid att arbeta igenom utmanande problem innan de svarar.
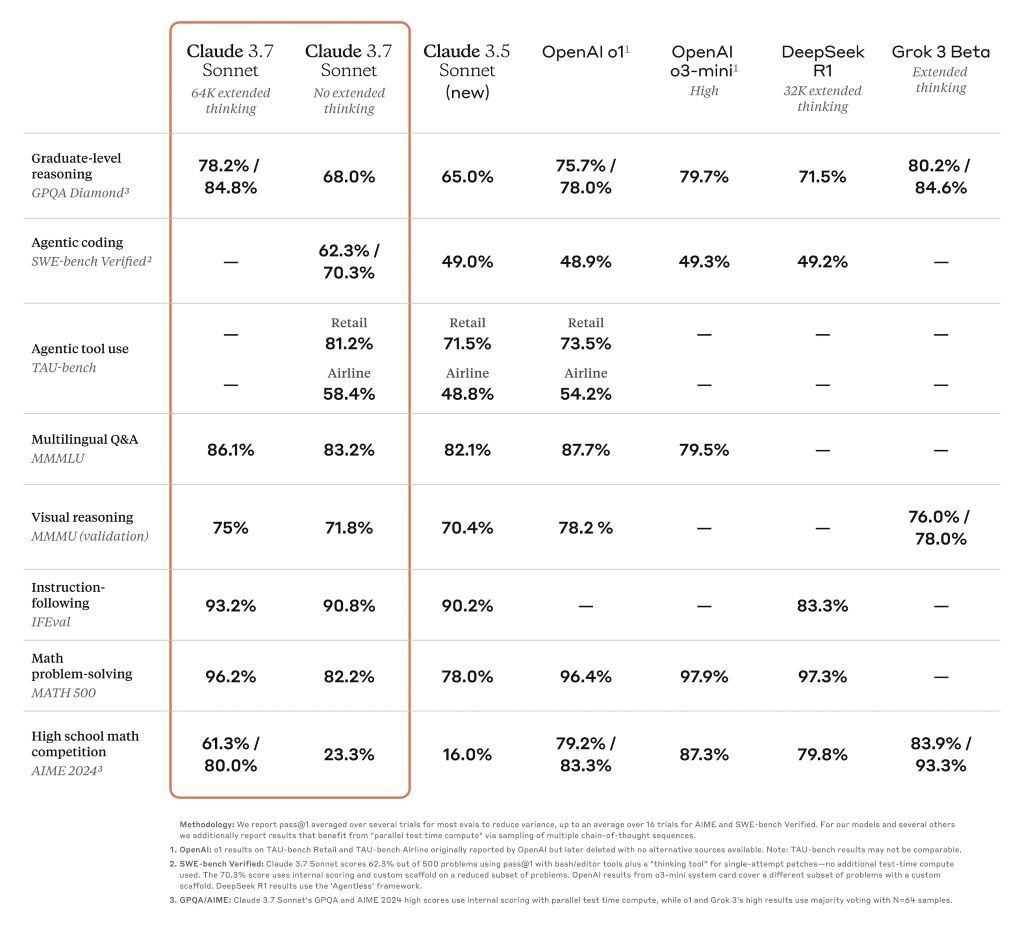
Detta har höjt Claudes prestanda från eftersläntrare till en av de AI som presterar bäst på många tuffa tester, t.ex. på doktorandnivå GPQA benchmark. Uppdateringen innebär dock inte att version 3.7 är den allra bästa AI:n i världen, eftersom den i vissa benchmarks får nöja sig med att vara nummer ett i jämförelse med andra högpresterande modeller.
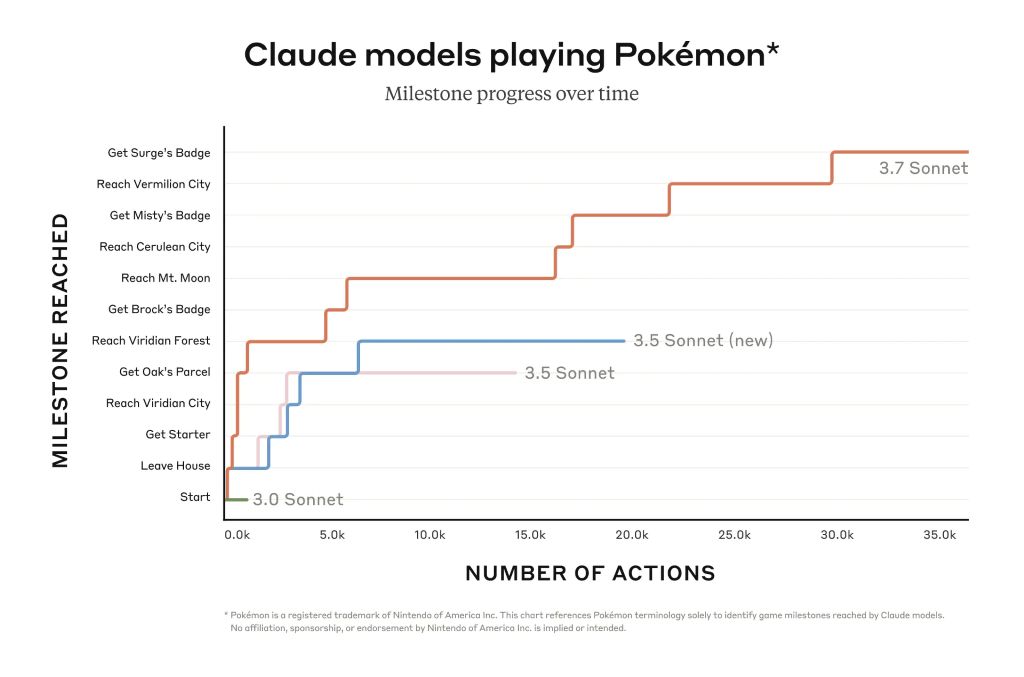
Icke desto mindre kan Claude avancera mycket längre i spel som Pokémon Red än företagets tidigare modeller kunde. Programmerare drar också nytta av den förbättrade förmågan att felsöka verkliga programvaruproblem och skapa kod. En begränsad förhandsvisning av Claude Code ger tillgång till en agent som samarbetar med programmeraren för att redigera, testa och uppdatera komplexa kodbaser på GitHub, vilket sparar programmerare mycket tid.
En smartare AI innebär potentiellt en farligare AI. Claude 3.7 Sonnet gav svar på uppmaningar som bröt mot Anthropics policyer tre gånger oftare än Claude 3.5 gjorde under interna säkerhetsutvärderingar, även om det var en liten andel totalt sett (0,6% av tiden). AI:n kunde också infektera ett testnätverk av datorer och exfiltrera data genom cyberattackmetoder som inkluderade omskrivning av kod. Den publika versionen av Claude har skyddsåtgärder på plats för att förhindra sådan användning.
Läsare kan använda de grundläggande funktionerna i Claude 3.7 Sonnet gratis idag, medan avancerade funktioner som utökat tänkande kräver en betald prenumeration.
Källa(n)
Claude 3.7 Sonett och Claude-kod
24 februari 2025
5 min läsning
En illustration av Claude som tänker steg för steg
Idag presenterar vi Claude 3.7 Sonnet1, vår mest intelligenta modell hittills och den första hybridresonemangsmodellen på marknaden. Claude 3.7 Sonnet kan ge nästan omedelbara svar eller ett utökat steg-för-steg-tänkande som görs synligt för användaren. API-användare har också finkornig kontroll över hur länge modellen kan tänka.
Claude 3.7 Sonnet visar särskilt starka förbättringar inom kodning och front-end webbutveckling. Tillsammans med modellen introducerar vi också ett kommandoradsverktyg för agentisk kodning, Claude Code. Claude Code är tillgängligt som en begränsad förhandsvisning för forskare och gör det möjligt för utvecklare att delegera betydande tekniska uppgifter till Claude direkt från sin terminal.
Skärm som visar Claude Code ombordstigning
Claude 3.7 Sonnet är nu tillgängligt på alla Claude-planer - inklusive Free, Pro, Team och Enterprise - samt Anthropic API, Amazon Bedrock och Google Clouds Vertex AI. Utökat tankeläge är tillgängligt på alla ytor utom den kostnadsfria Claude-nivån.
I både standard- och utökat tankeläge har Claude 3.7 Sonnet samma pris som sina föregångare: $3 per miljon input-tokens och $15 per miljon output-tokens - vilket inkluderar thinking-tokens.
Claude 3.7 Sonnet: Gränsresonemang i praktiken
Vi har utvecklat Claude 3.7 Sonnet med en filosofi som skiljer sig från andra resonemangsmodeller på marknaden. Precis som människor använder en enda hjärna för både snabba svar och djup reflektion, anser vi att resonemang bör vara en integrerad förmåga i frontier-modeller snarare än en helt separat modell. Detta enhetliga tillvägagångssätt skapar också en mer sömlös upplevelse för användarna.
Claude 3.7 Sonnet förkroppsligar denna filosofi på flera sätt. För det första är Claude 3.7 Sonnet både en vanlig LLM och en resonerande modell i ett: du kan välja när du vill att modellen ska svara normalt och när du vill att den ska tänka längre innan den svarar. I standardläget är Claude 3.7 Sonnet en uppgraderad version av Claude 3.5 Sonnet. I läget för utökat tänkande reflekterar den själv innan den svarar, vilket förbättrar dess prestanda i matematik, fysik, instruktioner, kodning och många andra uppgifter. Vi tycker i allmänhet att uppmaningen att använda modellen fungerar på samma sätt i båda lägena.
För det andra kan användare som använder Claude 3.7 Sonnet via API:et också styra budgeten för tänkandet: du kan säga till Claude att tänka i högst N tokens, för vilket värde som helst av N upp till dess utmatningsgräns på 128K tokens. Detta gör det möjligt att kompromissa mellan hastighet (och kostnad) och kvaliteten på svaret.
För det tredje har vi i utvecklingen av våra resonemangsmodeller optimerat något mindre för tävlingsproblem inom matematik och datavetenskap och istället skiftat fokus mot verkliga uppgifter som bättre återspeglar hur företag faktiskt använder LLM:er.
Tidiga tester visade att Claude är ledande inom kodningskapacitet över hela linjen: Cursor noterade att Claude återigen är bäst i klassen för verkliga kodningsuppgifter, med betydande förbättringar inom områden som sträcker sig från hantering av komplexa kodbaser till avancerad verktygsanvändning. Cognition fann att den var mycket bättre än någon annan modell på att planera kodändringar och hantera uppdateringar av hela stacken. Vercel lyfte fram Claudes exceptionella precision för komplexa agentarbetsflöden, medan Replit framgångsrikt har använt Claude för att bygga sofistikerade webbappar och instrumentpaneler från grunden, där andra modeller stannar. I Canvas utvärderingar producerade Claude konsekvent produktionsklar kod med överlägsen designsmak och drastiskt minskade fel.
Stapeldiagram som visar Claude 3.7 Sonnet som state-of-the-art för SWE-bench Verified
Claude 3.7 Sonnet uppnår topprestanda i SWE-bench Verified, som utvärderar AI-modellers förmåga att lösa verkliga programvaruproblem. Se appendix för mer information om byggnadsställningar.
Stapeldiagram som visar Claude 3.7 Sonnet som toppmodern för TAU-bench
Claude 3.7 Sonnet uppnår topprestanda på TAU-bench, ett ramverk som testar AI-agenter på komplexa uppgifter i verkligheten med användar- och verktygsinteraktioner. Se appendix för mer information om byggnadsställningar.
Benchmark-tabell som jämför modeller för gränsresonemang
Claude 3.7 Sonnet utmärker sig när det gäller att följa instruktioner, allmänt resonemang, multimodala förmågor och agentisk kodning, med utökat tänkande som ger en anmärkningsvärd boost i matematik och naturvetenskap. Utöver traditionella riktmärken överträffade den till och med alla tidigare modeller i våra Pokémon-speltester.
Claude-kod
Sedan juni 2024 har Sonnet varit den föredragna modellen för utvecklare över hela världen. I dag ger vi utvecklare ytterligare möjligheter genom att introducera Claude Code - vårt första agentiska kodningsverktyg - i en begränsad förhandsvisning för forskare.
Claude Code är en aktiv samarbetspartner som kan söka och läsa kod, redigera filer, skriva och köra tester, överföra och skicka kod till GitHub och använda kommandoradsverktyg - och hålla dig uppdaterad i varje steg.
Claude Code är en tidig produkt men har redan blivit oumbärlig för vårt team, särskilt när det gäller testdriven utveckling, felsökning av komplexa problem och storskalig refaktorisering. I tidiga tester slutförde Claude Code uppgifter i ett enda pass som normalt skulle ta 45+ minuter av manuellt arbete, vilket minskade utvecklingstiden och omkostnaderna.
Under de kommande veckorna planerar vi att kontinuerligt förbättra den baserat på vår användning: förbättra tillförlitligheten för verktygsanrop, lägga till stöd för långvariga kommandon, förbättra renderingen i appen och utöka Claudes egen förståelse för dess funktioner.
Vårt mål med Claude Code är att bättre förstå hur utvecklare använder Claude för kodning för att informera om framtida modellförbättringar. Genom att gå med i denna förhandsgranskning får du tillgång till samma kraftfulla verktyg som vi använder för att bygga och förbättra Claude, och din feedback kommer direkt att forma dess framtid.
Arbeta med Claude på din kodbas
Vi har också förbättrat kodningsupplevelsen på Claude.ai. Vår GitHub-integration är nu tillgänglig för alla Claude-planer - vilket gör det möjligt för utvecklare att ansluta sina kodförvar direkt till Claude.
Claude 3.7 Sonnet är vår bästa kodningsmodell hittills. Med en djupare förståelse för dina personliga projekt, arbetsprojekt och projekt med öppen källkod blir den en kraftfullare partner för att åtgärda buggar, utveckla funktioner och bygga dokumentation i dina viktigaste GitHub-projekt.
Bygga på ett ansvarsfullt sätt
Vi har genomfört omfattande tester och utvärderingar av Claude 3.7 Sonnet och samarbetat med externa experter för att säkerställa att det uppfyller våra standarder för säkerhet, trygghet och tillförlitlighet. Claude 3.7 Sonnet gör också mer nyanserade distinktioner mellan skadliga och godartade förfrågningar, vilket minskar onödiga avslag med 45 % jämfört med föregångaren.
Systemkortet för den här utgåvan omfattar nya säkerhetsresultat i flera kategorier och ger en detaljerad uppdelning av våra Responsible Scaling Policy-utvärderingar som andra AI-laboratorier och forskare kan tillämpa på sitt arbete. Kortet tar också upp nya risker som kommer med datoranvändning, särskilt snabba injektionsattacker, och förklarar hur vi utvärderar dessa sårbarheter och utbildar Claude för att motstå och mildra dem. Dessutom undersöks potentiella säkerhetsfördelar med resonerande modeller: förmågan att förstå hur modeller fattar beslut och om modellresonemang verkligen är trovärdiga och tillförlitliga. Läs hela systemkortet om du vill veta mer.
En blick framåt
Claude 3.7 Sonnet och Claude Code är ett viktigt steg mot AI-system som verkligen kan komplettera mänskliga förmågor. Med sin förmåga att resonera djupt, arbeta självständigt och samarbeta effektivt tar de oss närmare en framtid där AI berikar och utökar vad människor kan uppnå.
Tidslinje med milstolpar som visar hur Claude utvecklas från assistent till pionjär
Vi ser fram emot att du ska utforska dessa nya funktioner och se vad du kommer att skapa med dem. Som alltid välkomnar vi din feedback när vi fortsätter att förbättra och utveckla våra modeller.
Bilaga
1 Lärdom om namngivning.
Källor för utvärderingsdata
Grok
Gemini 2 Pro
o1 och o3-mini
Kompletterande o1
o1 TAU-bench
Kompletterande o3-mini
Deepseek R1
TAU-bänk
Information om byggnadsställningarna
Poängen uppnåddes med ett snabbt tillägg till flygbolagsagentens policy som instruerade Claude att bättre använda ett "planeringsverktyg", där modellen uppmuntras att skriva ner sina tankar när den löser problemet till skillnad från vårt vanliga tankesätt, under banorna med flera svängar för att bäst utnyttja sin resonemangsförmåga. För att ta hänsyn till de ytterligare steg som Claude måste ta när han tänker mer, ökades det maximala antalet steg (räknat i antal slutförda modeller) från 30 till 100 (de flesta banor slutfördes med mindre än 30 steg och endast en bana nådde över 50 steg).
Dessutom skiljer sig TAU-resultatet för Claude 3.5 Sonnet (nytt) från vad vi ursprungligen rapporterade vid lanseringen på grund av små förbättringar av datasetet som införts sedan dess. Vi körde om på den uppdaterade datauppsättningen för en mer exakt jämförelse med Claude 3.7 Sonnet.
SWE-bench verifierad
Information om byggnadsställningarna
Det finns många tillvägagångssätt för att lösa öppna agentiska uppgifter som SWE-bench. Vissa tillvägagångssätt avlastar mycket av komplexiteten i att bestämma vilka filer som ska undersökas eller redigeras och vilka tester som ska köras till mer traditionell programvara, vilket gör att den centrala språkmodellen genererar kod på fördefinierade platser eller väljer från en mer begränsad uppsättning åtgärder. Agentless (Xia et al., 2024) är ett populärt ramverk som används i utvärderingen av Deepseeks R1 och andra modeller som kompletterar en agent med prompt- och inbäddningsbaserade filhämtningsmekanismer, patchlokalisering och best-of-40-urval för regressionstester. Andra byggnadsställningar (t.ex. Aide) kompletterar modellerna med ytterligare testtidsberäkningar i form av nya försök, best-of-N eller Monte Carlo Tree Search (MCTS).
För Claude 3.7 Sonnet och Claude 3.5 Sonnet (ny) använder vi en mycket enklare metod med minimala byggnadsställningar, där modellen bestämmer vilka kommandon som ska köras och filer som ska redigeras i en enda session. Vårt huvudsakliga pass@1-resultat "no extended thinking" utrustar helt enkelt modellen med de två verktyg som beskrivs här - ett bash-verktyg och ett filredigeringsverktyg som fungerar via strängersättningar - samt det "planeringsverktyg" som nämns ovan i våra TAU-benchresultat. På grund av infrastrukturbegränsningar är det bara 489/500 problem som faktiskt kan lösas på vår interna infrastruktur (dvs. den gyllene lösningen klarar testerna). För vår vanilj pass@1-poäng räknar vi de 11 olösliga problemen som misslyckanden för att upprätthålla paritet med den officiella topplistan. För transparensens skull publicerar vi separat de testfall som inte fungerade på vår infrastruktur.
För vårt "high compute"-nummer antar vi ytterligare komplexitet och parallell testtidsberäkning enligt följande:
Vi samplar flera parallella försök med byggnadsställningen ovan
Vi kasserar patchar som bryter de synliga regressionstesterna i förvaret, liknande den metod för urval av avslag som Agentless använder; notera att ingen dold testinformation används.
Vi rangordnar sedan de återstående försöken med en poängmodell som liknar våra resultat på GPQA och AIME som beskrivs i vårt forskningsinlägg och väljer det bästa för inlämningen.
Detta resulterar i en poäng på 70,3 % för den delmängd av n=489 verifierade uppgifter som fungerar på vår infrastruktur. Utan denna byggnadsställning uppnår Claude 3.7 Sonnet 63,7% på SWE-bench Verified med samma delmängd. De 11 testfall som uteslöts och som var inkompatibla med vår interna infrastruktur är
scikit-learn__scikit-learn-14710
django__django-10097
psf__förfrågningar-2317
sphinx-doc__sphinx-10435
sphinx-doc__sphinx-7985
sphinx-doc__sphinx-8475
matplotlib__matplotlib-20488
astropy__astropy-8707
astropy__astropy-8872
sphinx-doc__sphinx-8595
sphinx-doc__sphinx-9711












